Abstract
This guide serves as a comprehensive resource for AI developers, MLOps engineers, data scientists, and technical leaders. It delves into Context Engineering, a crucial discipline for transitioning Large Language Model (LLM) applications from experimental demos to robust, accurate, and powerful production systems. A key focus is Agentic Retrieval-Augmented Generation (RAG), presented as an advanced paradigm that moves beyond simple retrieval to intelligent, self-correcting information processing. The NeuroFlux AGRAG system is showcased as a practical, open-source example, demonstrating these principles through its multi-tool RAG capabilities and strict grounding mechanisms, ensuring reliable LLM applications.
Executive Summary
The imperative for Context Engineering in 2025 is clear, driven by challenges such as LLM hallucination, rising operational costs, and the complexity of integrating real-world, diverse data. This guide introduces Agentic RAG, a significant evolution from traditional RAG, enabling LLMs to intelligently plan, evaluate, and refine their information gathering and synthesis process. NeuroFlux AGRAG is presented as a practical, open-source illustration of these core Context Engineering principles.
Key benefits of applying Context Engineering to Agentic RAG include: enhanced accuracy, significantly reduced hallucination, and efficient multi-source data integration (spanning unstructured documents, web content, and structured databases). This guidebook aims to bridge the gap between the immense potential of LLMs and the realities of production deployment, offering practical examples and actionable insights for building truly reliable and powerful AI systems.
Chapter 1: Context Engineering Through Brainstorming - Initiating Intelligent AI Projects
Before the first line of code is written or the first document indexed, effective Context Engineering begins with rigorous brainstorming. This chapter explores how structured brainstorming methodologies, traditionally human-centric, can be adapted and even augmented by AI to design robust RAG systems and define the optimal context flow for an LLM-powered project. It's about ensuring you ask the right questions of your data and your AI before you even begin building.
1.1 The Role of Brainstorming in Context Engineering
Brainstorming in Context Engineering is the critical initial phase where project stakeholders collaboratively define:
- The Problem: What specific, real-world challenge is the AI application meant to solve?
- The User Need: What information does the user truly seek, and in what format?
- The Data Landscape: What sources of information are available (structured, unstructured, real-time)?
- The "Why" Behind the "What": Understanding the underlying reasoning required for the AI to answer complex queries.
- The Definition of "Good Context": What constitutes relevant, accurate, and sufficient information for the LLM.
This phase moves beyond just ideation; it's about pre-engineering the context by anticipating the LLM's needs, identifying potential pitfalls, and mapping the informational journey required for a successful AI solution.
1.2 Types of Brainstorming for Context Engineering
Various brainstorming techniques can be employed, often in combination, to thoroughly explore the context landscape.
A. Traditional Brainstorming:
- Description: Free-flowing ideation, often in groups, where all ideas are welcomed without immediate judgment.
- Uses: Initial problem definition, identifying broad data sources, uncovering diverse user needs, exploring wild AI application ideas.
- How-to: Set a clear problem statement, encourage quantity over quality, build on others' ideas, defer judgment.
- Relevance to AI/LLM: Helps generate initial query types, identify potential data silos, and conceptualize the AI's persona.
B. Mind Mapping:
- Description: A visual technique that organizes ideas around a central concept, branching out into related sub-topics.
- Uses: Structuring complex queries, mapping data relationships (especially for potential Knowledge Graphs), outlining LLM reasoning paths, visualizing Context Engineering layers.
- How-to: Start with a central query/problem, branch out with keywords/short phrases, use colors/images for emphasis.
- Relevance to AI/LLM: Excellent for defining granular context needed by LLMs, visualizing how different data points connect for multi-hop queries, and designing database schemas.
C. Reverse Brainstorming (Problem Reversal):
- Description: Instead of asking "How can we solve X?", ask "How can we cause X?" or "How can we make X worse?". Then, reverse those ideas to find solutions.
- Uses: Identifying potential failure modes, anticipating hallucination risks, uncovering data biases, pinpointing security vulnerabilities in context flow.
- How-to: Define the problem, reverse it, brainstorm ways to achieve the reversed problem, then reverse those solutions.
- Relevance to AI/LLM: Crucial for proactive Context Engineering. Helps define guardrails, validation steps, and error handling mechanisms within the RAG pipeline.
D. SCAMPER Method (Substitute, Combine, Adapt, Modify, Put to another use, Eliminate, Reverse):
- Description: A checklist of idea-spurring questions applied to an existing idea or process.
- Uses: Innovating on existing RAG components, optimizing workflows, exploring new tool integrations, streamlining context delivery.
- How-to: Pick an element of your RAG (e.g., "Retriever"), then apply SCAMPER questions (e.g., "How can we Substitute the embedding model?").
- Relevance to AI/LLM: Excellent for refining Context Engineering layers, leading to improvements like hybrid search, re-ranking, or new data sources.
E. Role Storming / Persona Mapping:
- Description: Participants assume the role of different stakeholders or even the AI itself.
- Uses: Understanding diverse user needs for context, anticipating how the "Mind" or "Voice" LLM might interpret queries or generate responses, identifying ethical concerns from different perspectives.
- How-to: Assign roles (e.g., "the end user," "the data scientist," "the compliance officer," "the LLM agent"), then brainstorm from that perspective.
- Relevance to AI/LLM: Informs the design of user-facing outputs, prompt personas, and ethical guardrails.
1.3 The Brainstorming Process in AI/LLM Context Engineering
Integrating brainstorming into the Context Engineering workflow is a structured process:
Define the Core Problem & AI's Role:
- Clearly articulate what the AI system should do and for whom.
- Example: "Generate scholarly white papers on AI topics for researchers."
Map the Information Flow (High-Level):
- Sketch the journey of a query from user to final answer. (Similar to the NeuroFlux Trinity diagram, but initially very rough).
Identify Data Sources & Types:
- Brainstorm all possible sources: internal documents, web, databases, APIs.
- Categorize them: unstructured, structured, semi-structured.
Brainstorm Query Types & Complexity:
- What kinds of questions will users ask? Simple facts? Multi-hop reasoning? Trend analysis? Comparative analysis?
- How-to: Use mind mapping or persona mapping to generate a comprehensive list.
Define "Good" Output & Success Metrics:
- What constitutes a successful answer/report? Accuracy? Completeness? Timeliness? Verifiability?
- How-to: Use reverse brainstorming: "How could this report go wrong?" (e.g., hallucinate, be outdated, miss key points).
Brainstorm Context Components & Tools:
- Given the problem, queries, and desired output, what RAG components are needed? Vector DB? Re-ranker? SQL integration?
- How-to: Use SCAMPER on a basic RAG diagram. Brainstorm specific open-source tools for each component.
Anticipate Challenges & Design Safeguards:
- What are the risks (bias, privacy, cost, latency, hallucination, data staleness)?
- How-to:m Use reverse brainstorming.
- What Context Engineering principles apply here (no hallucination, strict grounding, validation)?
Prioritize & Prototype:
- Based on feasibility and impact, prioritize the Context Engineering components to implement first.
- Start with a Minimum Viable Product (MVP) and iterate.
1.4 Benefits of Brainstorming in Context Engineering
- Holistic Design: Ensures all aspects of context (acquisition, retrieval, synthesis, presentation) are considered from the outset.
- Proactive Problem Solving: Identifies potential data gaps, tool limitations, and ethical risks before costly development.
- Enhanced Accuracy & Reliability: By meticulously defining "good context," the system is designed from the ground up for factual grounding.
- Cost Efficiency: Optimizing context reduces unnecessary LLM token usage and computational load by ensuring only relevant information is processed.
- Innovation: Fosters creative solutions for complex information challenges, leading to novel Agentic RAG architectures.
- Stakeholder Alignment: Facilitates shared understanding and consensus among technical and non-technical teams on the AI's capabilities and limitations.
By investing in structured brainstorming, Context Engineering lays a robust foundation, transforming ambitious AI project ideas into concrete, reliable, and impactful intelligent applications, much like the journey undertaken in building NeuroFlux AGRAG.
Chapter 2: Understanding Context Engineering - The Foundation of Agentic AI
2.1 What is Context Engineering?
Imagine you have an incredibly smart assistant, far more capable than any human expert, yet with a peculiar limitation: its core knowledge, vast as it is, is fixed at a certain point in time, and it occasionally invents facts if it's unsure. Now, picture tasking this assistant with writing a detailed, factual report on a rapidly evolving topic – say, the latest breakthroughs in quantum computing, or the precise implications of a brand-new global trade agreement. Simply asking "Write a report on X" would yield outdated or inaccurate results.
This is where Context Engineering emerges as a critical discipline. It's the art and science of optimizing the entire information flow to and from an AI, ensuring it has precisely the right information, at the right moment, in the right format, with clear directives to produce truly accurate, reliable, and relevant outputs. It's about meticulously preparing the AI's "situation" for optimal performance, far beyond merely crafting a good initial question. You're not just prompting; you're orchestrating its access to and understanding of the world's most current and relevant data.
From an architectural standpoint, Context Engineering encompasses the complete pipeline of information management within an AI-driven application. This involves:
- Systematic Data Acquisition: Intelligently gathering diverse data from various sources—be it vast unstructured document repositories, dynamic web APIs, or precise structured databases.
- Intelligent Contextualization: Processing this raw, often messy, data into digestible units for the AI, ensuring semantic coherence and rich metadata.
- Strategic Retrieval: Employing sophisticated algorithms to efficiently pinpoint and extract the most pertinent pieces of information for any given query.
- Information Fusion: Seamlessly blending and prioritizing data from disparate origins into a cohesive context.
- Dynamic Prompt Construction: Generating prompts that are not static instructions but adaptive blueprints, precisely guiding the AI's reasoning, synthesis, and desired output format.
- Continuous Validation & Feedback: Implementing robust mechanisms to verify the factual accuracy and quality of both the intermediate computational steps and the final generated responses.
Ultimately, Context Engineering is the discipline that ensures AI systems are grounded in truth, operate efficiently, and deliver trusted results in complex, real-world scenarios.
2.2 Agentic RAG: The Evolution of Intelligent Retrieval
The landscape of AI is rapidly evolving, moving beyond simple question-answering to sophisticated Agentic AI. In this paradigm, Large Language Models (LLMs) are not merely passive responders; they become active agents capable of planning, reasoning, taking actions, and even engaging in iterative self-correction. Within this evolution, Retrieval Augmented Generation (RAG) takes on a new, critical dimension, becoming Agentic RAG.
Agentic RAG represents a significant leap forward from traditional RAG. While standard RAG retrieves information once and then generates a response, Agentic RAG empowers the LLM to:
- Iteratively Refine Searches: If an initial search doesn't yield satisfactory results, the LLM can rephrase queries, explore different data sources, or perform follow-up searches.
- Self-Evaluate: The LLM can assess the quality and completeness of its own retrieved context and generated responses, identifying gaps or potential inaccuracies.
- Plan Multi-Step Actions: For complex queries, the LLM can break down the problem, decide which tools (like searching a database or browsing the web) to use at each step, and then synthesize the findings.
This iterative, self-correcting behavior is vital for tackling highly complex, ambiguous, or multi-faceted queries that cannot be resolved with a single retrieval pass. It transforms the RAG system into a dynamic, problem-solving entity, significantly enhancing the reliability and depth of its outputs.
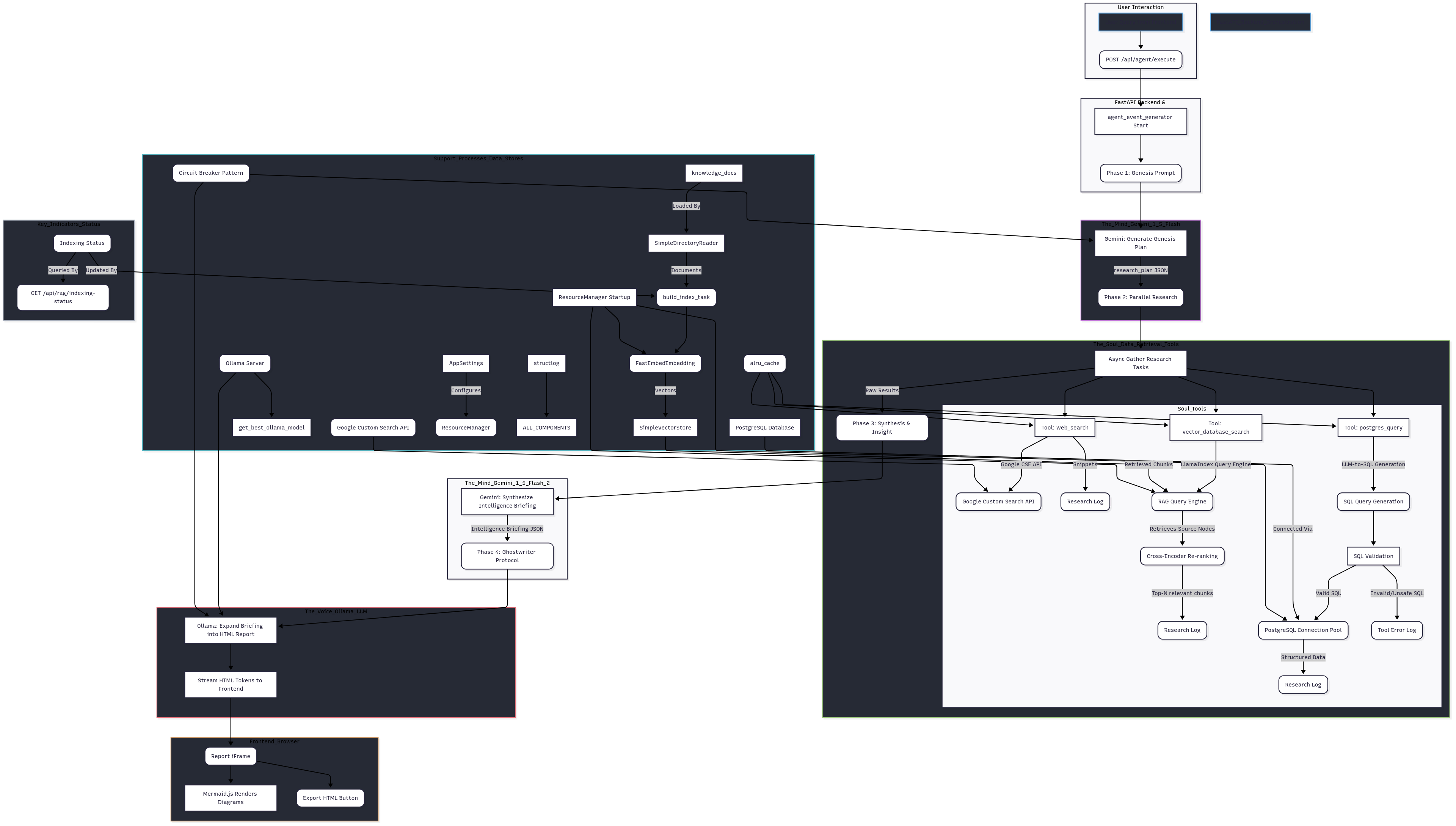
2.3 The NeuroFlux "Trinity" Architecture: An Agentic RAG Blueprint
The NeuroFlux AGRAG system is designed as a practical blueprint for Agentic RAG, embodying a "Trinity" architecture that orchestrates distinct AI roles in a seamless information pipeline. This structure facilitates sophisticated Context Engineering by clearly delineating responsibilities:
In NeuroFlux, each "agent" plays a specialized role in the Context Engineering process:
- The Mind (Strategist - powered by Google Gemini): This is the high-level orchestrator and intellectual core. It interprets the initial user query, formulates a multi-step research plan, and then synthesizes all raw information into a coherent, structured "Intelligence Briefing." This agent is crucial for understanding complex intent and setting the context for subsequent actions.
- The Soul (Memory - powered by Vector DBs, PostgreSQL, Web Search): This agent represents the system's access to external knowledge. It executes the research plan provided by the Mind, retrieving relevant information from diverse sources. This ensures the context is current, comprehensive, and factual.
- The Voice (Ghostwriter - powered by Ollama LLM): This agent is responsible for the final communication. It takes the meticulously synthesized "Intelligence Briefing" from the Mind and transforms it into a polished, detailed, and verifiable long-form report, adhering to specific formatting and scholarly standards.
This clear separation of concerns, orchestrated through intelligent prompts and tool selection, allows NeuroFlux to manage complex information flows, verify facts, and produce high-quality outputs—hallmarks of effective Agentic RAG.
2.4 The "Ghostwriter Protocol" in NeuroFlux: A Practical Agentic RAG Case Study
The "Ghostwriter Protocol" within NeuroFlux AGRAG serves as a compelling real-world case study for applied Context Engineering in an Agentic RAG system. Its primary mission: to generate "deep, insightful, and novel 'white paper' style reports" of "professional scholar investigative standards." This specific task inherently demands a level of accuracy, comprehensiveness, and analytical depth that pushes the boundaries of typical LLM applications.
For instance, when tasked with a query like, "Discuss how a RAG system mitigates temporal drift in LLM responses, and explain 'model alignment' as it relates to this mitigation," the Ghostwriter Protocol must:
- Strategize: The Mind must understand the multi-part query, identifying needs for both conceptual explanations (temporal drift, model alignment) and specific examples/frameworks.
- Research Broadly: The Soul must perform targeted searches across its document base and the web for relevant papers, definitions, and real-world tools.
- Synthesize Rigorously: The Mind must then distill this potentially vast and sometimes contradictory research into a coherent briefing, ensuring factual accuracy and precise definitions of complex terms.
- Generate with Precision: Finally, the Voice must expand this briefing into a structured HTML report, complete with explanations, sections on related work, and proper citations.
This end-to-end process showcases Context Engineering in action, demonstrating how orchestrating specialized AI components to manage, retrieve, synthesize, and present information effectively is paramount for achieving reliable, high-quality outcomes in advanced AI applications. The lessons learned from building and refining the Ghostwriter Protocol are directly applicable to any system aiming for similar levels of precision and trustworthiness in LLM-driven decision support.
Chapter 3: The Context Engineering "Master Class" - Building the Agentic RAG Layers
Building a sophisticated Agentic RAG system that consistently delivers reliable and accurate outputs requires a structured approach. Context Engineering, at its core, defines this architecture by dissecting the information flow into distinct, yet interconnected, operational layers. This "master class" outlines these five essential layers, providing a blueprint for designing your own intelligent RAG solutions.
3.1 Layer 1: Data Ingestion & Preparation Layer (The Agent's Sensory Input)
This foundational layer is responsible for transforming raw, disparate data into a clean, semantically rich format that is digestible for the subsequent RAG processes. It's akin to equipping an AI agent with high-fidelity sensory organs, ensuring its understanding of the world starts from a clear perception.
Purpose: To acquire data from various sources, parse it, and prepare it for efficient indexing and retrieval. This involves transforming unstructured and semi-structured documents into a format suitable for vectorization and contextual enrichment.
Key Components:
- Document Loaders: Tools to ingest data from diverse formats (PDFs, Markdown, text files, web pages, databases).
- Parsers: Specialized components to extract clean text from complex documents (e.g., from PDFs with multi-column layouts, tables, or images via OCR).
- Chunkers (Text Splitters): Algorithms that break down large documents into smaller, manageable, and semantically coherent units (chunks or nodes).
- Metadata Extractors: Processes that identify and attach relevant metadata (e.g., title, author, date, section, keywords) to each chunk. This metadata is crucial for filtered retrieval and providing richer context.
Key Principles of Context Engineering:
- Data Quality as a Prerequisite: The integrity and relevance of the source data directly dictate the upper bound of the RAG system's output quality. "Garbage In, Garbage Out" (GIGO) applies rigorously here.
- Semantic Chunking: Prioritizing chunking strategies that maintain the logical integrity of information units (e.g., keeping a full paragraph or a related set of bullet points together) over arbitrary character splits.
- Metadata Enrichment: Leveraging additional context about each chunk (its source, date, topic) to enhance retrieval precision and guide LLM synthesis.
NeuroFlux Example:
NeuroFlux utilizes SimpleDirectoryReader for document loading, supporting various formats. While lacking advanced parsers like Unstructured.io in its current stable build (a point for future enhancement), it emphasizes the importance of data source preparation. Its reliance on VectorStoreIndex.from_documents implies default chunking, but the principle of proper chunking for semantic coherence remains central to its Context Engineering philosophy.
3.2 Layer 2: Knowledge Storage & Indexing Layer (The Agent's Long-Term Memory)
Once data is prepared, this layer is responsible for efficiently storing and indexing it to enable rapid and intelligent retrieval. This is where the agent's vast "long-term memory" resides, allowing it to quickly access relevant facts when needed.
Purpose: To store the vectorized document chunks and their associated metadata in a way that facilitates lightning-fast similarity searches and structured queries.
Key Components:
- Vector Databases (Vector DBs): Purpose-built databases optimized for storing high-dimensional vector embeddings and performing Approximate Nearest Neighbor Search (ANNS). They allow for semantic search based on the meaning of the query.
- Traditional Relational Databases (RDBMS): Used for storing structured, transactional, and exact factual data. They are crucial for precise lookups, aggregations, and enforcing data integrity.
- Knowledge Graphs (Optional, Advanced): A structured representation of entities and their relationships. Can be integrated for highly precise, multi-hop logical reasoning and complex factual queries.
Key Principles of Context Engineering:
- Multi-Modal Storage: Recognizing that different types of knowledge require different storage paradigms (semantic for text, exact for numbers, relational for relationships).
- Efficient Indexing: Employing algorithms (e.g., HNSW, IVF for vector DBs; B-trees for RDBMS) that minimize search latency across massive datasets.
- Data Persistence & Scalability: Ensuring the knowledge base can grow and remain available over time, handling increasing data volumes and query loads.
NeuroFlux Example:
NeuroFlux demonstrates a multi-modal storage strategy:
- Vector Database: It currently uses
SimpleVectorStore for in-memory vector storage, allowing immediate experimentation. The intent, however, is to use persistent and scalable solutions like Qdrant (llama_index.vector_stores.qdrant.QdrantVectorStore), highlighting a common production choice.
- Relational Database: Integration with PostgreSQL (
asyncpg) is implemented for retrieving structured, exact facts (e.g., user records, product details) through LLM-generated SQL queries.
This dual-database approach ensures NeuroFlux can access both the conceptual breadth of unstructured data and the precision of structured records.
3.3 Layer 3: Retrieval & Re-ranking Layer (The Agent's Information Gathering)
This layer focuses on intelligently querying the knowledge base(s) and refining the retrieved results to ensure that only the most relevant and precise context is delivered to the LLM for synthesis. It represents the agent's discerning ability to gather exactly what it needs from its memory.
Purpose: To take a user's query, convert it into an effective search strategy, execute that search across relevant knowledge sources, and then filter/prioritize the results for optimal LLM consumption.
Key Components:
- Query Transformation/Expansion: Techniques (often LLM-driven) to rephrase, expand, or decompose the user's initial query to improve retrieval effectiveness.
- Multiple Retrievers: Utilizing different search mechanisms concurrently or conditionally (e.g., vector search for semantic similarity, keyword search for exact matches, SQL queries for structured data).
- Re-rankers: Post-retrieval models (often cross-encoders) that take an initial set of retrieved documents and re-score them for fine-grained relevance, selecting only the absolute best for the LLM's context.
Key Principles of Context Engineering:
- Adaptive Querying: Matching the query's complexity and data type to the appropriate retrieval mechanism.
- Precision Enhancement: Minimizing noise and maximizing the relevance of retrieved context to prevent the LLM from being distracted or overwhelmed.
- Context Window Optimization: Ensuring the LLM receives the most impactful information within its limited context window, thereby improving efficiency and reducing processing costs.
NeuroFlux Example:
NeuroFlux implements several critical techniques in this layer:
- Multi-Tool Retrieval: The "Mind" (via
genesis_prompt and research_plan) orchestrates run_web_search_tool (for broad, current info), run_rag_search_tool (for vector database lookups), and run_postgres_query_tool (for structured queries).
- Result Re-ranking: A CrossEncoder (
RERANKER) is applied after the initial vector retrieval (run_rag_search_tool) to re-score and select the top RERANK_TOP_N most relevant nodes, ensuring the LLM receives highly distilled context.
- LLM-Generated SQL: The
run_postgres_query_tool uses Gemini to generate SQL, which is then validated by sqlglot before execution, demonstrating a sophisticated form of query transformation for structured data.
3.4 Layer 4: Orchestration & Synthesis Layer (The Agent's "Brain")
This is the cognitive core of an Agentic RAG system, where the LLM agent actively processes information, makes decisions, and constructs coherent knowledge from disparate inputs. It's the "brain" that guides the entire Context Engineering process, from planning research to synthesizing raw data into actionable insights.
Purpose: To intelligently manage the flow of information across different tools and knowledge sources, guide the LLM's reasoning process, synthesize raw retrieved data into structured insights, and apply constraints to ensure reliable output.
Key Components:
- Agentic Frameworks: Software libraries that provide the infrastructure for building LLM agents capable of planning, executing actions (tool use), and iterating.
- Tooling/Tool Definition: Explicit definitions of the capabilities of external tools (like databases, search engines, APIs) that the LLM agent can "call."
- LLM Orchestrator (The "Mind"): A primary LLM responsible for interpreting complex user intent, generating multi-step plans, selecting the appropriate tools, and synthesizing the diverse results into a coherent, structured briefing.
Key Principles of Context Engineering:
- Prompt Chaining: Designing a sequence of prompts that guide the LLM through a complex task, with the output of one prompt serving as input for the next.
- Constraint Adherence: Rigorously enforcing rules on LLM output (e.g., JSON schema, specific data types, factual grounding) to ensure consistency and reliability.
- Iterative Reasoning: Enabling the LLM agent to evaluate its own progress, identify gaps or errors, and perform follow-up actions (e.g., re-searching, re-phrasing queries) to refine its understanding and improve accuracy. This is a hallmark of Agentic RAG.
- Multi-Tooling: Empowering the LLM to dynamically choose and integrate information from various specialized tools (e.g., vector DB for semantic search, RDBMS for exact facts, web search for currency).
NeuroFlux Example:
NeuroFlux's "Mind" (powered by Google Gemini) serves as the core orchestrator.
agent_event_generator: This function manages the entire multi-phase workflow, acting as the primary loop for the Agentic process.genesis_prompt: This prompt defines the "Mind's" strategic role, its available tools (web_search, vector_database_search, postgres_query with defined schema), and instructs it to generate a detailed research_plan with specific tool calls.synthesis_prompt: This critical prompt guides the Mind to synthesize the raw research_log into a structured intelligence_briefing JSON, rigorously extracting facts, metrics, and tool mentions, and adhering to strict "no hallucination" rules. This ensures the generated context for the next stage is both comprehensive and verifiable.
3.5 Layer 5: Generation & Presentation Layer (The Agent's Communication)
This final layer is where the meticulously engineered context culminates in a polished, user-ready output. It represents the agent's ability to communicate complex insights clearly, accurately, and in a desired format.
Purpose: To transform the synthesized, structured knowledge into a human-readable, professional, and verifiable final product. This often involves expanding concise briefings into long-form reports, ensuring stylistic consistency, and handling dynamic content like diagrams and citations.
Key Components:
- LLM Generators (The "Voice"): A primary LLM responsible for taking the distilled context from the orchestration layer and expanding it into the final output. This LLM is tuned for fluency, coherence, and adherence to stylistic guidelines.
- Output Formatters: Tools or prompts that ensure the generated content conforms to specific formats (e.g., HTML, Markdown, JSON, PDF), including styling and structural elements.
- Citation Managers: Mechanisms to track and attribute information back to its original sources, ensuring verifiability and building trust.
Key Principles of Context Engineering:
- Persona & Tone: Engineering the LLM to adopt a specific writing style, voice, and level of formality suitable for the target audience (e.g., scholarly, executive, conversational).
- Verifiability & Trust: Integrating strict rules for factual grounding and source attribution to combat hallucination and enhance user confidence in the AI's output. This is paramount for critical applications.
- User Experience (UX): Presenting complex information in a clear, accessible, and visually appealing manner, often involving dynamic elements like diagrams, tables, and interactive components.
NeuroFlux Example:
NeuroFlux's "Voice" (powered by a local Ollama LLM like mistral:latest or llama3:8b-instruct) is the primary component of this layer.
ghostwriter_prompt: This extensive prompt acts as the ultimate formatter and quality control. It dictates the exact HTML structure, the required sections (Abstract, Executive Summary, Related Work, etc.), and demands deep elaboration of the "Intelligence Briefing."- Dynamic Referencing: The
ghostwriter_prompt explicitly instructs the Voice to include in-text numerical citations [N] and to build a formatted "References" list from the verifiable_sources provided by the Mind.
- Mermaid Diagram Rendering: The prompt includes the Mermaid.js script and instructions for embedding valid Mermaid code, ensuring diagrams from the Mind are visually rendered in the final HTML report.
- No Hallucination Enforcement: The Voice is strictly forbidden from inventing facts not present in the "Intelligence Briefing," acting as the final guardian of factual integrity.
Chapter 4: The Tools of the Trade - A Comprehensive Overview
Building a robust Context Engineering system, especially an Agentic RAG architecture like NeuroFlux, relies heavily on a diverse ecosystem of specialized open-source and commercial tools. Selecting the right tools for each layer is crucial for balancing performance, scalability, flexibility, and operational simplicity. This chapter provides an overview of key tools, highlighting their benefits and detractors within the context of Context Engineering.
4.1 LLM Frameworks & APIs
These are the core intelligence engines that power the "Mind" and "Voice" layers.
Google Gemini (API - e.g., NeuroFlux's Mind):
- Benefits: Exceptional reasoning capabilities, strong adherence to complex prompt structures (e.g., JSON output), massive context windows, continuous updates, managed service (no local hardware/ops burden). Ideal for the "Mind's" strategic planning and complex synthesis.
- Detractors: Cloud API dependency (potential vendor lock-in), cost per token (can be high for very long prompts/responses), data privacy concerns (data leaves local environment).
Ollama (Local LLM Serving - e.g., NeuroFlux's Voice):
- Benefits: Runs LLMs entirely locally (privacy, data sovereignty), cost-free beyond hardware, supports a wide range of open-source models (Llama3, Mistral, Qwen), high control over inference. Ideal for the "Voice's" long-form, private content generation.
- Detractors: Requires local powerful hardware (GPU with sufficient VRAM), local setup and maintenance, model availability depends on community/Ollama platform.
Other Notable LLMs (Examples):
- Llama3 (Meta): State-of-the-art open-source model, highly capable for general reasoning and generation. (Can be run via Ollama).
- Mixtral (Mistral AI): High-performing Mixture-of-Experts model, known for efficiency and strong multi-lingual capabilities. (Can be run via Ollama).
- Claude (Anthropic): Known for strong reasoning, long context windows, and safety. (API-based).
4.2 Embedding Models
These models convert raw data (text, images) into dense vector representations, forming the language of vector databases.
FastEmbed (e.g., NeuroFlux's Embeddings):
- Benefits: Extremely fast and efficient for embedding generation, supports various state-of-the-art open-source models, runs locally, optimized for performance. Low memory footprint.
- Detractors: Less flexible for highly custom embedding tasks compared to raw Hugging Face Transformers. Specific device parameter issues were a notable (and now resolved for NeuroFlux) setup challenge in some versions.
BAAI/bge-small-en-v1.5 (e.g., NeuroFlux's Model):
- Benefits: A high-performing general-purpose embedding model from the BGE family, known for strong performance on semantic similarity benchmarks. Relatively small size for efficient local use.
- Detractors: Primarily English-focused, might not be optimal for highly niche or multi-lingual domains without fine-tuning.
Other Notable Embeddings (Examples):
- OpenAI Embeddings: High quality, easy API access, widely used. (API-based, cost).
- Cohere Embed: Strong commercial embeddings, often good for enterprise. (API-based, cost).
- E5-base/large: Another family of strong open-source embedding models, good performance-to-size ratio.
4.3 Vector Databases (for unstructured data)
These are the specialized databases for storing and querying vector embeddings efficiently.
SimpleVectorStore (e.g., NeuroFlux's current development DB):
- Benefits: Extremely easy to set up (no external services, pure Python), good for rapid prototyping and small-scale testing.
- Detractors: In-memory only (data is lost on restart), not persistent, not scalable for large datasets (will exhaust RAM), no advanced features. Not suitable for production.
Qdrant (e.g., NeuroFlux's intended persistent DB):
- Benefits: Offers native hybrid search (vector + keyword), rich payload filtering (querying metadata), scalable (can be clustered), supports REST and gRPC APIs. Good for structured filtering on unstructured data.
- Detractors: Requires external setup (Docker or dedicated server for production), can be resource-intensive, LlamaIndex integration had persistent versioning/import conflicts (a key learning from NeuroFlux's journey).
Milvus:
- Benefits: Designed for massive-scale vector data (tens of billions of vectors), cloud-native architecture, supports diverse indexing algorithms (HNSW, IVF), offers hybrid search. Strong community.
- Detractors: Can be resource-intensive to operate and manage, high operational complexity for self-hosting.
Faiss (Facebook AI Similarity Search):
- Benefits: Raw, in-memory performance (often fastest), GPU optimized, highly memory-efficient through compression (e.g., Product Quantization). Great for research and prototyping large-scale ANNS.
- Detractors: A library, not a standalone service (no built-in persistence, distribution), steeper learning curve due to low-level control. More integration work needed.
Weaviate:
- Benefits: Hybrid approach combining vector search with a knowledge graph, supports semantic relationships, GraphQL API. Good for contextual enrichment.
- Detractors: Added complexity due to graph model, performance might not match pure vector DBs for ultra-low latency, can be more resource-intensive for complex graph queries.
Chroma:
- Benefits: Designed for simplicity and LLM application integration, easy-to-use Python API, lightweight, often good for quick RAG demos.
- Detractors: Newer project, less mature ecosystem and battle-tested at extreme scales compared to Milvus/Qdrant.
pgvector:
- Benefits: Extends PostgreSQL to add vector data types and operations. Allows combining vector search with traditional SQL queries, leveraging existing PostgreSQL infrastructure and expertise (cost-effective for existing PG users).
- Detractors: Performance may not match dedicated vector databases for very large vector collections or extremely high query volumes. It's a pragmatic compromise rather than an optimized solution for vector-only workloads.
Elasticsearch (kNN):
- Benefits: Adds vector search to an existing, widely adopted text search platform. Good for teams already invested in the Elastic ecosystem.
- Detractors: Not purpose-built for vector search, performance may not match dedicated vector databases for large-scale, vector-only workloads.
4.4 Relational Databases & SQL Options
These databases are the backbone for structured, transactional data, crucial for precise factual retrieval in Agentic RAG when combined with LLM-to-SQL capabilities.
PostgreSQL (e.g., NeuroFlux's Structured DB):
- Benefits: Open-source, highly robust, ACID-compliant, extensive features (JSONB, full-text search, extensibility via pgvector), large community, widely used in enterprise. Excellent for structured data, complex joins, and aggregations.
- Detractors: Can be resource-intensive for very large analytical workloads without proper tuning, requires dedicated server setup/management.
MySQL / MariaDB:
- Benefits: Widely popular, open-source, easy to set up, good for web applications, strong community support.
- Detractors: Less feature-rich than PostgreSQL for advanced data types or complex analytical queries, scalability can be more challenging for massive datasets compared to specialized distributed DBs.
SQLite:
- Benefits: Serverless (database is a file), zero-configuration, extremely lightweight, ideal for embedded applications, local development, and simple data storage.
- Detractors: Not suitable for concurrent multi-user access, limited scalability, lacks advanced features like network access controls or user roles.
SQL Server (Microsoft):
- Benefits: Robust, high-performance, integrates well with Microsoft ecosystem, comprehensive tooling (SSMS), strong transactional capabilities.
- Detractors: Proprietary (licensing costs), primarily Windows-based, steeper learning curve for non-Microsoft developers.
Oracle Database:
- Benefits: Enterprise-grade, highly scalable (handles massive data/transactions), extremely robust, comprehensive security features, high availability.
- Detractors: Very high licensing costs, complex to set up and manage, resource-intensive.
4.5 RAG Option Types (Methodologies & Architectures)
Beyond specific tools, RAG can be implemented using various architectural patterns and advanced methodologies to improve performance, accuracy, and reliability. These are the "styles" of RAG.
Naive/Basic RAG (Retrieval-then-Generation):
- Description: The simplest form. A query comes in, a retriever fetches a fixed number of top-k documents/chunks, and these are directly concatenated into the LLM's prompt for generation.
- Benefits: Easy to implement, serves as a strong baseline, immediately reduces hallucinations compared to pure LLM.
- Detractors: Prone to "lost in the middle" (LLM misses info in long contexts), sensitive to retrieval quality (garbage in, garbage out), no self-correction.
Re-ranking RAG (e.g., NeuroFlux's Implementation):
- Description: An enhancement to Basic RAG. After initial retrieval, a dedicated re-ranker model scores the relevance of each retrieved chunk against the query. Only the highest-scoring chunks are passed to the LLM.
- Benefits: Significantly improves the precision of context, reduces noise, leads to more accurate and concise LLM responses, helps mitigate "lost in the middle."
- Detractors: Adds an extra inference step (latency), requires an additional re-ranker model.
Query Transformation/Expansion RAG:
- Description: The user's original query is transformed (e.g., rephrased, expanded with synonyms, broken into sub-questions) by an LLM before retrieval, to ensure more effective search.
- Benefits: Improves recall, handles ambiguous or complex user queries better, facilitates multi-hop reasoning.
- Detractors: Adds LLM call latency, transformation can introduce errors/hallucinations, requires careful prompt engineering for the transformation LLM.
Hybrid Retrieval RAG:
- Description:
Combines different retrieval methods (e.g., vector search for semantic similarity, keyword search for exact matches) to get a more comprehensive set of initial results.
- Benefits: Maximizes recall by leveraging strengths of different search types, particularly effective for queries with mixed semantic and keyword intent.
- Detractors: Adds complexity in merging/normalizing scores from different retrievers.
Agentic/Iterative RAG (e.g., NeuroFlux's Orchestration Principle with Mind/Soul/Voice):
- Description: The LLM (acting as an agent) doesn't just retrieve once. It plans, executes tool calls (search, retrieve, database query), evaluates intermediate results, and iteratively refines its research and generation process until a satisfactory answer is formed. This includes self-correction.
- Benefits: Handles highly complex, multi-hop, and ambiguous queries with greater reliability, reduces hallucinations through self-evaluation, allows dynamic tool use.
- Detractors: Significantly higher computational cost (multiple LLM calls, tool executions), increased latency, complex to design and debug, requires robust agentic frameworks.
Knowledge Graph (KG) Augmented RAG:
- Description: Integrates a structured knowledge graph. Retrieval can involve querying the KG directly for precise facts and relationships, or using KG embeddings alongside vector embeddings, or retrieving documents based on KG traversals.
- Benefits: Excellent for complex logical reasoning, multi-hop questions, and enforcing factual consistency. Provides strong traceability and explainability for factual components.
- Detractors: Extremely complex and costly to build and maintain the knowledge graph (especially for large, dynamic datasets), requires specialized expertise.
Multi-Modal RAG:
- Description: Extends RAG to handle non-textual data (images, audio, video). Queries can be text-based, but retrieved context includes relevant images, video segments, or audio clips, often with their own embeddings.
- Benefits: Enables AI applications that understand and generate across different modalities, crucial for fields like computer vision, medical imaging, and robotics.
- Detractors: High computational cost (multi-modal embeddings, storage), complex data pipelines, requires specialized multi-modal models.
Retrieval-Augmented Generation with Memory (Conversational RAG):
- Description: Extends RAG for multi-turn conversations by managing and retrieving context from past turns or explicit memory stores, ensuring coherence and continuity.
- Benefits: Enables natural, extended conversations with LLMs, maintains context over long interactions, improves user experience in chatbots and virtual assistants.
- Detractors: Complexity of managing conversational state, potential for memory drift, privacy concerns with persistent conversation history.
4.6 RAG Orchestration Frameworks & Agentic Tooling
These frameworks provide the scaffolding to build, connect, and manage the complex components of an Agentic RAG system, enabling the LLM to act as an intelligent orchestrator.
LlamaIndex (e.g., NeuroFlux's RAG Integration & Agentic Building Block):
- Benefits: Highly data-centric, excellent for building and querying knowledge indexes (vector stores, graph stores), extensive integrations with various data loaders, LLMs, and vector databases. Provides robust abstractions for constructing RAG pipelines and serves as a strong foundation for agentic behavior.
- Detractors: Very rapid development means frequent API changes and versioning challenges (a key learning point from NeuroFlux's journey, necessitating careful dependency management). Can sometimes feel more "data-centric" than "agent-centric" for complex reasoning flows without additional layering.
LangChain:
- Benefits: Extremely popular and versatile, offers comprehensive toolkits for building LLM applications, strong emphasis on agentic capabilities, chain design (sequences of LLM calls and tool uses), and prompt templating. Broad integrations across almost every LLM, tool, and database.
- Detractors: Can introduce a significant abstraction overhead ("LangChain-isms"), making debugging complex workflows challenging. The sheer breadth of features can be overwhelming for newcomers.
DSPy:
- Benefits: A new paradigm for "programming" LLMs, allowing developers to declaratively define complex LLM workflows (like multi-stage RAG, query transformation, self-correction) and then "compile" them into optimized prompts and weights. Focuses on optimizing LLM use for specific tasks rather than just static prompting.
- Detractors: Newer framework with a steeper learning curve, requires a shift in thinking from traditional programming, less mature ecosystem than LangChain/LlamaIndex.
4.7 SQL Integration & Validation Libraries
These tools facilitate secure and reliable interaction between LLMs and structured relational databases.
asyncpg (e.g., NeuroFlux's PostgreSQL Driver):
- Benefits: An asynchronous PostgreSQL driver for Python, optimized for high performance and concurrency. Essential for non-blocking database operations in FastAPI.
- Detractors: Requires a running PostgreSQL server, steeper learning curve than synchronous drivers.
sqlglot (e.g., NeuroFlux's SQL Validator):
- Benefits: A powerful and versatile SQL parser, transpiler, and optimizer. Crucial for robustly validating LLM-generated SQL against schemas, identifying syntax errors, and enforcing security policies (e.g., preventing DML/DDL). Supports various SQL dialects.
- Detractors:
Adds a layer of complexity for validation logic; defining comprehensive validation rules (especially for complex schemas) can be intricate.
4.8 General Utilities & Infrastructure
These supporting tools ensure the entire system is performant, robust, and manageable.
FastAPI (e.g., NeuroFlux's Web Framework):
- Benefits: Modern, fast (built on Starlette and Pydantic), asynchronous-first, excellent for building APIs. Automatic OpenAPI (Swagger UI) documentation.
- Detractors: Less opinionated than some full-stack frameworks, requiring more manual setup for certain features.
httpx (e.g., NeuroFlux's HTTP Client):
- Benefits: Modern, fully asynchronous HTTP client. Ideal for making non-blocking API calls (e.g., to Google Search, Ollama) within an asyncio application.
- Detractors: None major for its intended use.
async_lru (e.g., NeuroFlux's Caching):
- Benefits: Provides a simple, decorator-based in-memory cache for asynchronous functions. Excellent for reducing latency on repeated external API calls.
- Detractors: In-memory only (cache clears on restart), can cause RuntimeError if applied incorrectly to streaming functions (a specific NeuroFlux learning point).
pybreaker (e.g., NeuroFlux's Circuit Breaker):
- Benefits: Implements the Circuit Breaker pattern, enhancing resilience by preventing cascading failures to external services (e.g., Google API, Ollama) during temporary outages.
- Detractors: Requires careful configuration of failure thresholds and reset timeouts.
structlog (e.g., NeuroFlux's Logging):
- Benefits: Enables structured, machine-readable (JSON) logging. Essential for efficient log parsing, analysis, and debugging in complex distributed systems.
- Detractors: Slightly more setup boilerplate than basic Python logging.
sentence-transformers (e.g., NeuroFlux's Re-ranker):
- Benefits: Provides easy access to state-of-the-art pre-trained sentence and cross-encoder models for embedding and re-ranking, simplifying the use of these advanced techniques.
- Detractors: Models can be large, requiring significant VRAM/RAM for loading.
Mermaid.js (e.g., NeuroFlux's Diagramming):
- Benefits: A powerful JavaScript library for generating diagrams (flowcharts, sequence diagrams, etc.) from simple text-based code. Excellent for visualizing complex AI workflows and making reports more engaging.
- Detractors: Requires explicit HTML/JavaScript integration in the frontend for rendering.
Chapter 5: Building Agentic RAG with NeuroFlux (A Practical Guide)
This chapter walks through the practical steps of setting up and operating an Agentic RAG system, using the NeuroFlux AGRAG codebase as a concrete example. It highlights the crucial configuration points and operational considerations.
5.1 Setting up Your Local NeuroFlux Environment
A robust development environment is the first step in successful Context Engineering.
Prerequisites:
- Python: Version 3.9+ (Python 3.10 is used in NeuroFlux examples).
- Virtual Environment (venv): Essential for dependency isolation.
- Git: For version control (if cloning from a repository).
- Ollama: Running locally to serve open-source LLMs (e.g.,
mistral:latest, llama3:8b-instruct).
- PostgreSQL Database: Installed and running locally (via EDB installer or Docker), with a configured database (e.g.,
neuroflux_db) and user (e.g., NeuroFlux).
Dependency Management: The "Clean Install" Lesson:
For bleeding-edge AI projects, dependency conflicts (especially in LlamaIndex, as experienced) are common. The most reliable method to resolve them is a complete environment reset: deactivate -> rm -rf venv -> pip cache purge -> python -m venv venv -> source venv/bin/activate.
Follow with a consolidated pip install of all necessary packages, allowing pip to resolve compatible versions (e.g., pip install llama-index as a meta-package, alongside explicit installs for asyncpg, sqlglot, sentence-transformers, and google-generativeai).
.env Configuration:
Create a .env file in your main.py's directory. This file centralizes sensitive credentials and environment-specific paths.
GOOGLE_API_KEY="YOUR_GOOGLE_API_KEY_HERE"
GOOGLE_CSE_ID="YOUR_GOOGLE_CSE_ID_HERE" # Optional, for web search
OLLAMA_API_BASE="http://localhost:11434" # Adjust if Ollama is elsewhere
KNOWLEDGE_BASE_DIR="knowledge_docs" # Folder for your unstructured documents
PERSIST_DIR="storage" # Where Qdrant (if enabled) or other persistent data is stored
# PostgreSQL Connection (MUST match your local PG setup)
POSTGRES_HOST="localhost"
POSTGRES_PORT=5432
POSTGRES_USER="NeuroFlux"
POSTGRES_PASSWORD="your_neuroflux_password"
POSTGRES_DB="neuroflux_db"
Ensure knowledge_docs and storage (or your PERSIST_DIR) folders physically exist in your project root.
5.2 Data Preparation: Populating the Agent's Long-Term Memory
The quality and organization of your raw data directly determine the depth and accuracy of your Agentic RAG system's output.
Unstructured Data (knowledge_docs):
- Content: Place your detailed documents (e.g., academic papers, technical white papers, in-depth articles about AI, LLMs, RAG, vector databases, etc.) in the
knowledge_docs folder.
- Format Strategy: Prioritize Markdown (MD) for documents you control, as its inherent structure (headings, lists) allows for more semantic chunking. For existing PDFs, acknowledge their parsing complexity; the system will use
SimpleDirectoryReader's default text extraction, which can be noisy for complex layouts.
Structured Data (PostgreSQL):
- Schema & Population: Ensure your PostgreSQL database (
neuroflux_db) has the users, products, and orders tables created, and is populated with sample data. This is done via SQL commands executed in psql or pgAdmin 4.
- Alignment: The schema defined in
main.py's POSTGRES_SCHEMA_DEFINITION must precisely match the actual tables and columns in your PostgreSQL database.
Indexing the Knowledge Base:
- Action: After starting your Uvicorn server (
uvicorn main:app), navigate to the frontend (http://127.0.0.1:8000).
- Click the "Index Knowledge Base" button. This triggers the
build_index_task in your backend.
- Verification: Crucially, monitor your Uvicorn terminal logs. You must see messages indicating "Scanning document directory...", "Building vector index...", and finally ✅ RAG 'Soul' initialized (in-memory). (or "Qdrant" if Qdrant is re-enabled). This confirms your RAG system has successfully processed and indexed your documents into its in-memory vector store for the current session.
5.3 Orchestrating the Agent: The Mind's Strategic Playbook
This section delves into how an Agentic RAG system leverages the reasoning capabilities of a powerful LLM (the "Mind") to strategically plan information gathering, execute research, and intelligently synthesize results. This is where Context Engineering truly enables dynamic, multi-step problem-solving.
5.3.1 The Agentic Workflow: Guiding Information Flow
NeuroFlux's agent_event_generator function serves as the central orchestrator, managing the lifecycle of a user query from initial interpretation to final report generation. It implements a multi-phase process, allowing the "Mind" to dictate the flow of context.
- Initial Query Interpretation: The process begins with a user's natural language query. The "Mind" (Gemini) is tasked with understanding the query's intent, identifying key entities, and recognizing what types of information (unstructured documents, structured database records, live web data) will be required.
- Dynamic Research Planning: Based on this interpretation, the "Mind" creates a
research_plan. This plan is not static; it's a dynamic list of actions, each specifying a tool_to_use (e.g., web_search, vector_database_search, postgres_query) and a query_for_tool. This demonstrates the Agentic capability of planning.
5.3.2 Crafting the genesis_prompt: Defining the Agent's Mandate
The genesis_prompt is the first and most critical prompt in the Agentic RAG pipeline. It establishes the "Mind's" persona, outlines its available tools, and sets the high-level objectives for its research plan. Effective Context Engineering at this stage ensures the agent starts on the right strategic path.
Purpose: To clearly define the "Mind's" role (strategist, master storyteller), inform it of the available data sources and their capabilities (e.g., database schema for PostgreSQL), and guide it to generate a structured research_plan that meticulously addresses the user's query.
Key Prompt Elements:
- Persona and Goal: "You are a master storyteller and strategist... create the narrative and strategic context."
- Tool Definitions: Explicitly listing each tool (
web_search, vector_database_search, postgres_query) with a brief description of its function.
- Schema Context: For structured tools like
postgres_query, providing the database schema (table names, column names, relationships) directly within the prompt is crucial. This allows the LLM to generate syntactically and semantically correct SQL.
- Output Format: Instructing the LLM to output a JSON object containing
backstory, core_tension, stakeholders, and the vital research_plan.
5.3.3 Executing Research Tasks: The "Soul" in Action
Once the "Mind" has generated its research_plan, the NeuroFlux system's "Soul" components spring into action, executing the planned data retrieval tasks. This phase gathers all the raw context needed for synthesis.
- Parallel Execution: Tasks in the
research_plan are executed concurrently using asyncio.gather. This speeds up the research phase by allowing multiple searches (e.g., web and local RAG) to happen in parallel.
- Dynamic Tool Calling: The
agent_event_generator dynamically calls the appropriate tool function (run_web_search_tool, run_rag_search_tool, run_postgres_query_tool) based on the tool_to_use specified in the "Mind's" plan.
- Robust Error Handling: Each tool call (
run_web_search_tool, run_rag_search_tool, run_postgres_query_tool) includes specific try-except blocks to catch and log errors (e.g., API failures, database connection issues, SQL validation errors). This ensures that a single failed research task does not crash the entire agent workflow.
- Caching (
alru_cache): Expensive tool calls (web search, RAG search, PostgreSQL queries) are cached using @alru_cache. This significantly reduces latency for repeated or similar research tasks within a session.
5.3.4 Synthesizing Insights: The Agent's Internal Monologue
After collecting all raw research results, the "Mind" re-engages to synthesize this potentially vast and disparate information into a coherent, structured "Intelligence Briefing." This step is where raw context transforms into actionable knowledge.
Crafting the synthesis_prompt:
This prompt guides the "Mind" (Gemini) to perform the intellectual heavy lifting:
- Deep Comprehension: Instructing it to analyze the
research_log (which contains all raw research results) for core insights.
- Structured Extraction: Explicitly demanding the extraction of specific elements into JSON keys:
title, executive_summary, core_analysis, novel_synthesis (with name and description), perspectives, verifiable_quotes, verifiable_sources, and mermaid_code.
- The "No Hallucination" Rule (Crucial): This prompt contains the stringent instruction that all facts, statistics, and tool names must be explicitly verifiable from the
research_log. This is the cornerstone of NeuroFlux's commitment to factual grounding. If specific data is missing, the Mind is instructed to use qualitative language or state the absence of data, preventing fabrication.
- Mermaid Syntax Enforcement: The prompt explicitly guides the Mind to generate Mermaid code in a syntactically correct format (
graph TD, sequenceDiagram, etc.), ensuring the diagrams will render in the final report.
The output of this phase, the intelligence_briefing JSON, is the distilled, verified context that the "Voice" will use to generate the final white paper. It's the critical link that translates raw data into a structured narrative.
Chapter 6: Agentic Communication: Shaping the Final Report
This chapter focuses on the "Voice" agent's role in translating the meticulously engineered context into a polished, verifiable, and professional final report. This is where Context Engineering ensures the agent's insights are effectively communicated to the human user.
6.1 Shaping the Narrative: The "Voice" LLM's Output Protocol
The "Voice" (a local Ollama LLM like Mistral or Llama3) is responsible for expanding the concise intelligence_briefing into a detailed, long-form HTML white paper. Its Context Engineering challenge is to maintain fidelity to the briefing while generating fluent, well-structured prose.
The ghostwriter_prompt:
This is the most extensive and prescriptive prompt in the entire system. It acts as the ultimate formatter and quality control for the final output.
- Absolute Structural Enforcement: The prompt dictates the exact HTML structure of the report, including all section and h2 tags (Abstract, Executive Summary, Related Work, etc.). This ensures consistency with scholarly paper formats.
- Deep Elaboration: It instructs the "Voice" to expand on the points from the
intelligence_briefing, providing detailed explanations, "why" analysis, and elaborating on technical specifics. The LLM is encouraged to weave the synthesized information into a compelling narrative.
- Dynamic Content Insertion: Placeholders like
{intelligence_briefing.get('title', ...)} allow the report to dynamically incorporate the specifics synthesized by the "Mind."
6.2 Integrating Visuals: Mermaid Diagrams for Clarity
Visual communication is a key aspect of effective Context Engineering, especially for complex systems.
- Diagram Generation: The "Mind" (via
synthesis_prompt) is tasked with generating Mermaid code if a relevant process or architecture is part of the query's answer.
- Rendering in Frontend: The
ghostwriter_prompt includes the Mermaid.js library and initialization script directly in the HTML output. The app.js frontend then ensures this script executes after the report content is loaded, transforming the textual Mermaid code into rendered diagrams within the browser. This makes complex Agentic RAG workflows understandable at a glance.
6.3 Verifiability & Citations: The Academic Standard
A cornerstone of Context Engineering for scholarly or critical applications is ensuring the output is verifiable and grounded in authoritative sources.
- Source Tracking: The "Mind" extracts
verifiable_sources (URLs from web search) into the intelligence_briefing.
- Dynamic References Section: The
ghostwriter_prompt forces the "Voice" to process these verifiable_sources into a formal "References" section at the end of the report, using a standardized format.
- In-text Citations [N] (Advanced Challenge): The
ghostwriter_prompt instructs the "Voice" to generate in-text numerical citations (e.g., [1]) whenever information derived from a specific source is used. This remains one of the most challenging aspects for current LLMs to perform perfectly and consistently without explicit source mapping. However, the instruction is present to push the LLM towards this critical scholarly standard.
- No Hallucination Enforcement: The "Voice" is strictly forbidden from inventing facts or references not present in the
intelligence_briefing, reinforcing the system's commitment to factual integrity. This ensures that if specific data isn't found, the report honestly reflects that gap, rather than fabricating content.
6.4 Performance Optimization (Practical Application within Agentic RAG)
Context Engineering also encompasses optimizing the practical execution of the Agentic RAG system.
- Caching (
alru_cache): Expensive external tool calls (run_web_search_tool, run_rag_search_tool, run_postgres_query_tool) are cached. This significantly reduces latency for repeated queries or for multi-step agentic workflows where the same sub-query might occur.
- Cross-Encoder Re-ranking: The CrossEncoder (
RERANKER) acts as a quality filter, ensuring that the "Voice" receives only the most precise and relevant chunks from the "Soul." This directly impacts output quality and can reduce the total context length the LLM needs to process, indirectly improving speed.
- Dynamic LLM Selection:
get_best_ollama_model ensures the "Voice" uses the most performant available local LLM, optimizing local compute resources.
Chapter 7: Optimizing & Evolving Your Agentic RAG System
The journey of Context Engineering doesn't end with a deployed system; it's a continuous cycle of optimization, evaluation, and adaptation. This chapter outlines key strategies for refining your Agentic RAG system and exploring future frontiers.
7.1 Key Performance Indicators (KPIs) for Production Agentic RAG
Beyond basic latency, evaluating Agentic RAG requires a nuanced set of metrics to ensure true reliability and effectiveness.
- Faithfulness/Groundedness: Measures how well the generated response is supported by the retrieved source documents. This directly combats hallucination. Tools like RAGAS (Retrieval Augmented Generation Assessment) provide automated metrics for this.
- Answer Relevance: Assesses how well the generated answer directly addresses the user's query.
- Context Relevance: Evaluates how relevant the retrieved documents actually are to the query.
- Completeness: Determines if the answer covers all aspects of a multi-faceted query.
- Tool Usage Efficiency: Monitors how often the agent uses the correct tool for a given sub-task, and how successful those tool calls are.
- Overall Latency & Throughput: Measures the end-to-end response time for complex, multi-step queries and the number of queries processed per second.
- Cost Efficiency: Tracks token usage across all LLM calls (Mind, Voice, SQL Generation), compute consumption (CPU/GPU), and external API costs.
7.2 Operational Insights & Lessons Learned from NeuroFlux's Journey
The development of NeuroFlux AGRAG provided invaluable practical lessons in the challenges and solutions of Context Engineering.
- Dependency Management: The "LlamaIndex pip install saga" highlighted the critical importance of rigorous version pinning for external libraries, especially in fast-moving AI ecosystems. Clean virtual environments (venv) and frequent cache purges are essential practices.
- Debugging Agentic Workflows: Multi-step LLM reasoning can be opaque. Robust, structured logging (
structlog) is paramount for tracing the agent's thought process, tool calls, and data flow, enabling efficient debugging of silent failures or incorrect reasoning.
- The Power of Data: The realization that "LLMs are only as good as the context they receive" was a core lesson. Investing in high-quality, structured data (e.g., converting TXT to MD, populating PostgreSQL) is more impactful than endlessly tweaking prompts if the underlying data is sparse or poorly organized.
- Pragmatism vs. Perfection: Balancing the desire for a theoretically perfect architecture with the practical need to get a system running and delivering value. Sometimes, temporary compromises (like using in-memory RAG) are necessary to overcome integration hurdles and build incrementally.
7.3 Future Frontiers in Agentic Context Engineering
The field of Context Engineering is rapidly advancing, with exciting new areas for exploration and implementation.
- Autonomous Agentic Loops: Developing LLM agents that can operate with greater autonomy, engaging in truly self-correcting and iterative research-and-refine cycles without constant human intervention. Frameworks like DSPy are pushing this boundary.
- Knowledge Graphs in Agentic Reasoning: Deeper integration of structured knowledge graphs to enable more precise, multi-hop logical reasoning and provide explicit traceability for complex factual inferences.
- Multi-Modal Agentic RAG: Extending Agentic RAG to process and synthesize information across various modalities, including images, video, and audio, allowing agents to understand and respond in rich, multi-sensory contexts.
- Active Learning & Human-in-the-Loop (HITL): Implementing mechanisms where human feedback on agent performance (e.g., accuracy, relevance) is used to continuously improve the RAG pipeline, the agent's planning, or even fine-tune the underlying LLMs.
7.4 NeuroFlux: An Open-Source Blueprint for the Future
NeuroFlux AGRAG stands as a living example of applied Context Engineering principles for Agentic RAG systems. It is designed not just as a functional tool, but as a robust and transparent blueprint for developers and researchers.
By open-sourcing NeuroFlux, the aim is to:
- Provide a practical, extensible codebase for learning and experimentation.
- Foster community collaboration in addressing the challenges of building reliable LLM applications.
- Contribute to the collective understanding of Context Engineering best practices.
The journey of Context Engineering is dynamic and ongoing. Through continuous learning, iterative development, and open collaboration, we can build the next generation of intelligent, trustworthy AI systems that effectively leverage diverse data sources to deliver profound insights.
Chapter 8: Latent Space Engineering - The Art of Semantic Precision
While Context Engineering broadly defines the end-to-end information flow for Agentic RAG, a crucial sub-discipline that directly impacts the quality and efficiency of retrieval is Latent Space Engineering. This field focuses on optimizing the numerical representations (embeddings) of data, ensuring that the "semantic map" understood by our AI systems is as accurate, relevant, and robust as possible. It's about meticulously crafting the very fabric of meaning within your RAG system's memory.
8.1 Understanding Latent Space
At its core, a latent space (or embedding space) is a low-dimensional vector space where data points (e.g., text, images, audio) are represented as dense numerical vectors. The key characteristic is that data points with similar meanings or properties are located closer to each other in this space, while dissimilar points are further apart.
- High-Dimensionality to Low-Dimensionality: Raw data (a sentence, an image) is inherently high-dimensional. Embedding models compress this into a vector with hundreds or thousands of dimensions.
- Semantic Closeness: The magic of latent space is that cosine similarity (or other distance metrics) between vectors directly correlates to the semantic similarity between the original data items. If two documents are about the same topic, their embeddings will be "close" in the latent space.
- Learned Representations: These embeddings are not arbitrary; they are learned by neural networks trained on vast amounts of data to capture complex patterns and relationships.
For RAG systems, latent space is the literal "language" through which the system understands what chunks of information are "relevant" to a given query.
8.2 Why Latent Space Engineering for RAG?
Optimizing the latent space is paramount for Agentic RAG systems for several critical reasons:
- Enhanced Retrieval Precision: The better the embeddings, the more accurately the vector database can retrieve truly relevant documents for a given query. Poor embeddings lead to "misses" or retrieval of irrelevant information.
- Reduced Hallucination & Improved Grounding: By ensuring retrieved context is highly relevant and semantically precise, the LLM is less likely to invent facts or stray from the provided information. It provides a stronger factual foundation.
- Context Window Optimization: Accurate retrieval means the LLM receives only the most salient information, minimizing the need for large context windows and reducing computational costs and latency.
- Nuanced Knowledge Representation: A well-engineered latent space can capture subtle semantic distinctions, allowing the RAG system to handle complex queries that require deep understanding of domain-specific terminology or abstract concepts.
- Multi-Modal Capabilities: As RAG evolves to incorporate images, audio, and video, a unified latent space allows for cross-modal search and synthesis (e.g., querying text to retrieve relevant images).
8.3 Key Pillars of Latent Space Engineering
Latent Space Engineering involves a range of techniques applied at different stages of the RAG pipeline:
8.3.1 Embedding Model Selection & Domain Adaptation
- Choosing the Right Base Model: Not all embedding models are created equal. Models like BGE (as used in NeuroFlux), OpenAI Embeddings, or Cohere Embed are chosen based on their performance on general semantic similarity benchmarks, their size, and their suitability for specific domains (e.g., scientific, legal, financial).
- Fine-tuning for Domain Specificity: For highly specialized domains, off-the-shelf embeddings may not capture nuances. Techniques include:
- Supervised Fine-tuning: Training the embedding model further on a curated dataset of relevant document-query pairs or positive/negative examples (e.g., using contrastive learning, triplet loss). This teaches the model to place domain-relevant similar items closer together.
- Unsupervised Adaptation (e.g., Retrofitting): Adjusting pre-trained embeddings using domain-specific knowledge graphs or lexical resources to push related terms closer in the latent space without labeled data.
8.3.2 Chunking & Metadata Strategy
- Semantic Chunking: The way documents are broken into chunks directly impacts their embeddings. Arbitrary chunking (e.g., fixed character count) can split semantically coherent units. LSE emphasizes techniques that preserve meaning within chunks (e.g., paragraph-based, recursive splitting by headings, sentence window retrieval where small chunks are embedded but full sentences/paragraphs are retrieved).
- Metadata Embedding: Incorporating metadata (source, date, author, topic tags) either directly into the chunk text before embedding (simpler approach) or by using hybrid retrieval that combines vector search with metadata filtering (more robust). This enriches the latent representation with structured context.
8.3.3 Query Embedding Optimization
- Query Rewriting/Expansion: An initial user query might be ambiguous or too short. An LLM (like NeuroFlux's "Mind") can rewrite or expand the query to make it more explicit and semantically rich before it is embedded. This helps the query vector land closer to relevant document vectors.
- Multi-Vector Queries: For complex queries, generating multiple embeddings (e.g., one for each sub-question) and performing multiple searches, then combining results, can improve recall.
8.3.4 Latent Space Manipulation & Refinement
- Re-ranking (Post-Retrieval Refinement): While not directly altering the latent space, re-rankers (like NeuroFlux's CrossEncoder) play a crucial role in LSE by re-scoring the initial retrieved documents. They act as a more granular semantic filter, ensuring that even if the initial retrieval casts a wide net in the latent space, only the most relevant "neighbors" are actually passed to the LLM.
- Embedding Compression/Quantization: Reducing the dimensionality or precision of embeddings (e.g., from float32 to float16 or int8) can significantly reduce storage and improve retrieval speed in vector databases with minimal impact on semantic accuracy.
- Latent Space Visualization & Analysis: Tools like t-SNE or UMAP allow visualizing high-dimensional latent spaces in 2D or 3D, helping engineers understand how their data is clustered, identify outliers, or spot potential biases in the learned representations.
8.4 Latent Space Engineering in NeuroFlux
NeuroFlux AGRAG implicitly and explicitly leverages Latent Space Engineering principles:
- Chosen Embedding Model: NeuroFlux uses
FastEmbed with the BAAI/bge-small-en-v1.5 model. This is a direct LSE choice, selecting a performant, open-source model optimized for general semantic similarity.
- Chunking and Indexing: The system relies on LlamaIndex's default chunking during
VectorStoreIndex.from_documents, which applies a recursive semantic splitting. While basic, it demonstrates the principle of breaking data into embeddable units.
- Re-ranking: The integration of a
CrossEncoder for re-ranking retrieved nodes is a prime example of LSE in action. It refines the initial "Soul" (vector database) search results, ensuring only the most semantically aligned documents, as determined by the re-ranker's deeper understanding of query-document relevance, reach the "Mind."
- Query Transformation (Implicit LSE): The "Mind's" ability to generate optimized
query_for_tool within its research_plan effectively performs query embedding optimization. By crafting precise and comprehensive queries for the vector database, it ensures the query's embedding is ideally positioned in the latent space to retrieve the most relevant information.
8.5 Challenges and Future Directions
Latent Space Engineering is not without its challenges:
- Computational Cost: Fine-tuning embedding models can be resource-intensive, requiring specialized hardware (GPUs) and significant data.
- Evaluation Complexity: Quantifying the "goodness" of a latent space or the impact of LSE techniques requires sophisticated metrics (e.g., hit rate, MRR, NDCG) and often human evaluation.
- Bias Propagation: Biases present in the training data of embedding models can be amplified and reflected in the latent space, leading to biased retrieval outcomes.
- Dynamic Latent Spaces: As data evolves, the latent space needs to be continuously updated. This involves re-embedding new or updated documents and potentially retraining/adapting the embedding model.
Future directions in LSE include self-improving embedding models that adapt based on RAG system feedback, more sophisticated multi-modal fusion in latent space, and techniques for creating truly "interpretable" latent spaces where specific dimensions correspond to human-understandable attributes.
By diligently applying Latent Space Engineering principles, developers can ensure their Agentic RAG systems are built on a foundation of highly accurate and semantically rich information, leading to more intelligent, reliable, and trustworthy AI applications.